Solusi Heteroskedastisitas pada Model Regresi: Aplikasi Robust Standard Error dengan Eviews dan STATA
Artikel ini menyajikan contoh aplikasi robust standard error
untuk kasus heteroskedastisitas pada hasil estimasi model regresi. Paket program
pengolahan data yang digunakan untuk simulasi adalah Eviews dan STATA.
Sebagai contoh, dalam artikel ini penulis mengestimasi model
regresi yang menjelaskan hubungan antara pengeluaran untuk konsumsi makanan (food
expenditure) dan pendapatan rumah tangga (income). Spesifikasi model adalah
sebagai berikut:
FOOD_EXP = α + βINCOME + ε
Hasil estimasi model di atas dengan Eviews dan STATA adalah
sebagai berikut:


Diagnosa awal dengan scatter plot INCOME dan RESIDUAL (estimasi)
menunjukkan indikasi kuat bahwa asumsi homoskedastisitas terlanggar. Terlihat
jelas bahwa varians RESIDUAL semakin besar seiring peningkatan pendapatan rumah
tangga. Hal ini wajar karena dengan meningkatnya pendapatan, rumah tangga
memiliki banyak pilihan dan pertimbangan terkait konsumsi.

Hasil diagnosis secara visual sejalan dengan hasil uji
statistik dengan menggunakan Breusch-Pagan/Cook-Weisberg test yang menyimpulkan
bahwa komponen error tidak homoskedastis. Hipotesis null bahwa error
homoskedastis tertolak pada tingkat signifikansi 1 persen.
Breusch-Pagan / Cook-Weisberg test for heteroskedasticity
Ho: Constant variance
Variables: fitted values of FOOD_EXP
chi2(1) = 7.34
Prob > chi2 = 0.0067
Seperti telah dijelaskan pada artikel sebelumnya, kondisi
ini mengakibatkan hasil estimasi koefisien regresi tidak lagi efisien. Selain
itu, standard error yang dihasilkan tidak lagi benar secara statistik.
Konsekuensinya, inferensia statistik (estimasi selang kepercayaan dan pengujian
hipotesis) tidak bisa dilakukan. Jika dipaksakan, kesimpulan yang diperoleh
bakal menyesatkan dan tidak bermakna.
Kabar baiknya, robust standard error menyediakan solusi
untuk persoalan ini. Meski hasil estimasi koefisien regresi tetap tidak
efisien, inferensia statistik tetap bisa dilakukan. Dengan menerapkan robust standard
error, pada dasarnya kita hanya mengoreksi perhitungan standard error tanpa mengubah
hasil estimasi koefisien regresi.
Bagaimana cara melakukannya?
Jika Anda menggunakan Eviews, caranya adalah sebagai berikut:
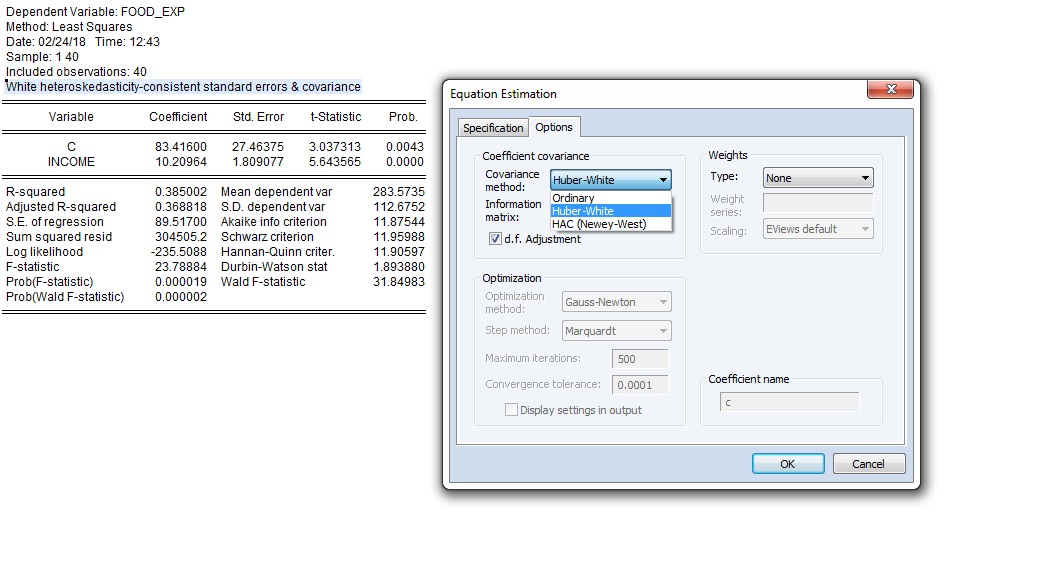
Saat mengestimasi model, pada menu “options” silakan pilih Huber-White untuk Covariance Method. Dengan pilihan ini, Eviews akan mengoreksi hasil perhitungan standard error sehingga dapat digunakan untuk inferensia statistik dan isu heteroskedastisitas dapat diabaikan. Hasilnya adalah sebagai berikut:
Jika Anda menggunakan Eviews, caranya adalah sebagai berikut:
Saat mengestimasi model, pada menu “options” silakan pilih Huber-White untuk Covariance Method. Dengan pilihan ini, Eviews akan mengoreksi hasil perhitungan standard error sehingga dapat digunakan untuk inferensia statistik dan isu heteroskedastisitas dapat diabaikan. Hasilnya adalah sebagai berikut:
Jika Anda menggunakan STATA, caranya sangat mudah, yakni
dengan menambahkan vce(robust) pada syntax yang digunakan untuk mengestimasi
model regresi. Dengan syantax ini kita meminta kepada STATA untuk melakukan
koreksi terhadap standard error seperti yang dilakukan Eviews sebelumnya.
Hasilnya adalah sebagai berikut:

Dapat Anda lihat bahwa aplikasi robust standard error hanya
merubah standard error dan statistik uji (t-stat dan p-value) dari estimasi koefisien
regresi. Adapun hasil estimasi koefisien regresi tetap tidak berubah.
Dengan menerapkan robust standard error, kita telah
menyelesaikan masalah pelik yang timbul akibat terlanggarnya asumsi homoskedastisitas meski hasil estimasi koefisien regresi tetap tidak
efisien. Lalu bagaimana penerapan robust standard error untuk kasus serial
correlation pada model regresi? Nantikan artikel berikutnya.

permisi pak, saya ingin bertanya apakah ada contoh cara penggunaan eviws untuk robust standar error? dan bagaiamana cara membaca outputnya? terimakasih :)
BalasHapusPortable EVIEWS 12 Full Version
BalasHapusVisit
s.id/Eviews12